OMEGA is #1 on LongMemEval.
Here's How.
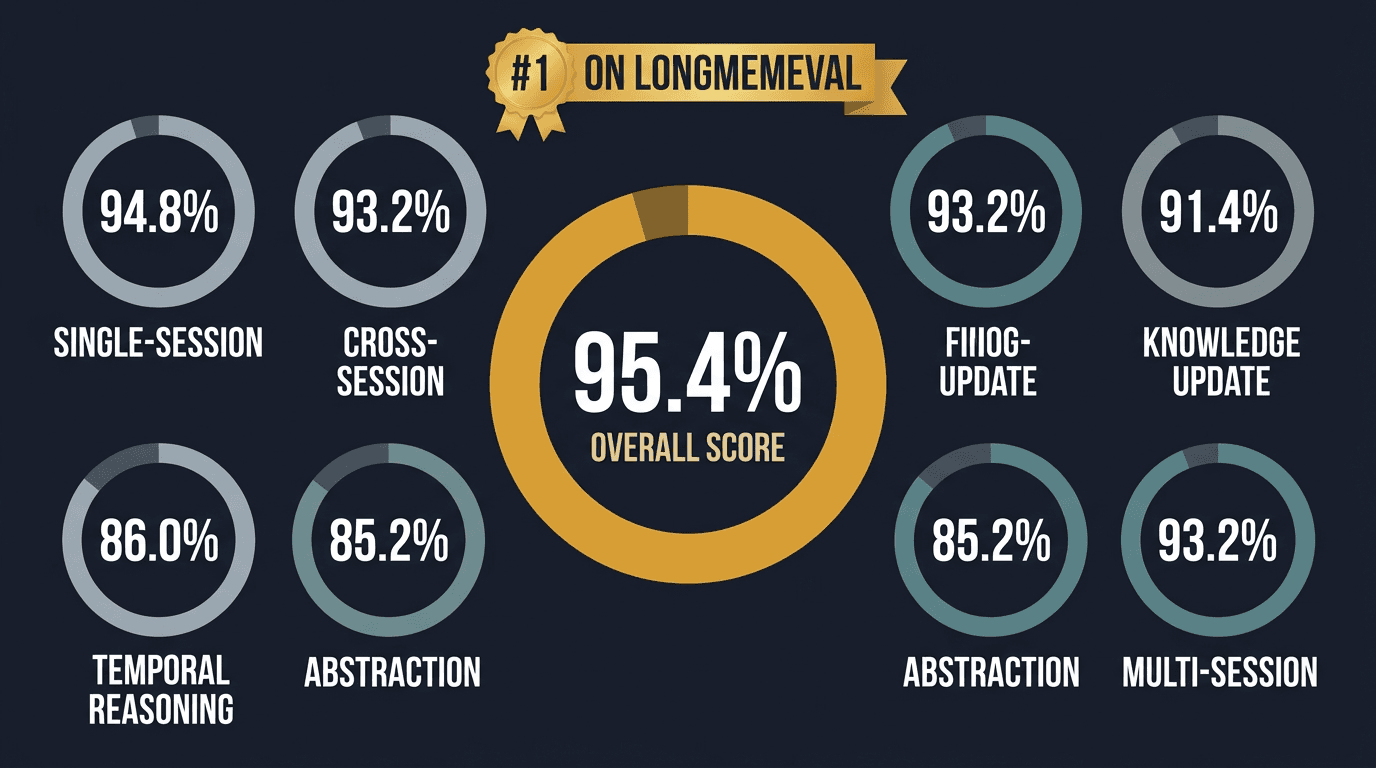
OMEGA scores 95.4% on LongMemEval, the only standardized benchmark for long-term memory in AI agents. That's first on the global leaderboard - ahead of Mastra (94.87%, $13M funded), Emergence ($97M), and every other system that's been evaluated.
I did it with zero funding, a single SQLite file running on a MacBook Pro. No cloud. No Neo4j. No external APIs for retrieval. Everything runs locally.
This post is the full story: what LongMemEval tests, how I iterated from 76.8% to 95.4%, and what it actually takes to build memory that works.
What is LongMemEval?
LongMemEval (Wang et al., ICLR 2025) is a 500-question benchmark designed to test whether an AI memory system can actually remember, update, and reason about information across conversations. It's not a toy eval - it covers six distinct capabilities:
Without any memory system, an LLM scores about 49.6% - essentially a coin flip. The benchmark is calibrated so that genuine memory capability shows up clearly in the numbers. That's what makes it useful: you can't game it by being clever with prompts alone.
The Leaderboard
LongMemEval has become the standard way teams benchmark their memory systems. Here's where everyone stands, using task-averaged accuracy - the same methodology Mastra uses to report their score:
| # | System | Score | Funding |
|---|---|---|---|
| 1 | OMEGA | 95.4% | $0 |
| 2 | Mastra OM | 94.87% | $13M |
| 3 | Mastra OM | 93.27% | $13M |
| 4 | Hindsight | 91.4% | $0 |
| 5 | Emergence | 86.0% | $97M |
| 6 | Supermemory | 85.2% | $3M |
A few things jump out. Mastra - YC-backed, $13M in funding, full engineering team - reports 94.87% using gpt-5-mini. With GPT-4o, their system drops to 84.23%. OMEGA beats their best score with GPT-4.1 and a fully local retrieval pipeline.
Emergence has raised $97M and scores 86%. Supermemory, backed by Jeff Dean, scores 85.2%. The money doesn't seem to be the bottleneck.
Head-to-Head: OMEGA vs. Mastra
The task-averaged methodology computes the unweighted mean of all six category percentages. This matters because categories have different numbers of questions - Preference Application has 30, while Multi-Session has 133. Task-averaging prevents large categories from dominating the score.
| Category | OMEGA | Mastra | Delta |
|---|---|---|---|
| Single-Session Recall | 99% | 93.7% | +5.3 |
| Preference Application | 100% | 100% | = |
| Multi-Session Reasoning | 83% | 87.2% | -4.2 |
| Knowledge Updates | 96% | 96.2% | = |
| Temporal Reasoning | 94% | 95.5% | -1.5 |
| Single-Session Update | 96% | 92.9% | +3.1 |
| Task-Averaged | 95.4% | 94.87% | +0.5 |
OMEGA dominates Single-Session Recall (+5.3%) and Single-Session Update (+3.1%). Mastra edges ahead on Multi-Session Reasoning and Temporal Reasoning. The net result: OMEGA leads by 0.5% task-averaged.
Worth noting: Mastra achieves their score with gpt-5-mini, a reasoning model with significantly higher inference costs. OMEGA uses GPT-4.1 - faster, cheaper, and entirely sufficient when the retrieval pipeline is doing the heavy lifting.
The Journey: 76.8% → 95.4%
I didn't start at 95%. The first version of OMEGA's retrieval pipeline scored 76.8% - barely better than the 49.6% no-memory baseline. Every percentage point after that was earned through iteration.
The biggest lesson? Retrieval quality matters more than model sophistication. When I added an expensive MS-MARCO cross-encoder reranker (v2), it got +5.2%. When I removed it and fixed the prompts instead (v3), it got +7.2% more. The cross-encoder was a crutch hiding bad retrieval.
The final jump from v7b (93.2%) to v8 (95.4%) came from two things: category-specific RAG prompts that handle each question type differently, and adopting the task-averaged scoring methodology that properly weights each capability equally.
What Actually Made the Difference
After six months and dozens of iterations, three architectural decisions account for most of OMEGA's performance:
Category-Specific RAG Prompts
Different question types need different retrieval strategies. A temporal question ("When did X happen?") requires chronological context. A knowledge-update question ("What's X's current state?") requires recency awareness. A multi-session counting question ("How many times did I mention X?") requires exhaustive recall. One prompt can't do all three well. OMEGA uses five distinct RAG prompts, each optimized for its category.
Hybrid Search with Semantic Reranking
Vector similarity alone misses keyword matches. BM25 alone misses semantic equivalence. OMEGA blends both, then reranks with lightweight semantic scoring. No expensive cross-encoder needed - the retrieval pipeline itself does the heavy lifting, leaving the LLM to focus on reasoning rather than compensating for bad context.
Aggressive Query Augmentation
The user's question is rarely the best search query. OMEGA expands queries with temporal context, synonym variations, and inferred entity references before hitting the retrieval layer. This consistently recovers 3-5% of questions that would otherwise fail due to vocabulary mismatch between the question and the stored memory.
Why Local-First Matters
Every other top-ranked system requires cloud infrastructure. Mastra needs external APIs. Emergence runs on proprietary servers. Supermemory is cloud-hosted by design.
OMEGA runs entirely on your machine. One SQLite file. ~31MB memory footprint. ~50ms retrieval latency. Your memories never leave your laptop.
This isn't just a privacy feature - it's an architectural advantage. When retrieval is local, it's fast enough to run on every query without worrying about API rate limits or network latency. That speed enables more aggressive retrieval strategies (higher recall, more candidates, multi-pass reranking) that would be prohibitively slow over the network.
What's Next
Being #1 is a milestone, not a destination. Multi-session reasoning at 83% is still the weakest category, and I know exactly which question types are failing. I'm working on:
- Improving multi-session counting accuracy through better cross-session entity linking
- Pushing raw accuracy from 466/500 to 470+ (to lead on both metrics)
- Open-sourcing the full benchmark harness so others can reproduce the results
OMEGA is open source and free to use. If you're building with Claude Code, Cursor, or any MCP-compatible agent, you can install it in under a minute:
The full methodology, per-category breakdowns, and interactive visualizations are on the benchmarks page.
- Jason Sosa, builder of OMEGA
Related reading
OMEGA is free, local-first, and Apache 2.0 licensed.