Why Your Agent Forgets: From RAG to Reflexive Memory
RAG gave agents access to documents. Agentic RAG let them decide when to search. Agent memory let them write things down. But none of that matters if the memory never improves itself.
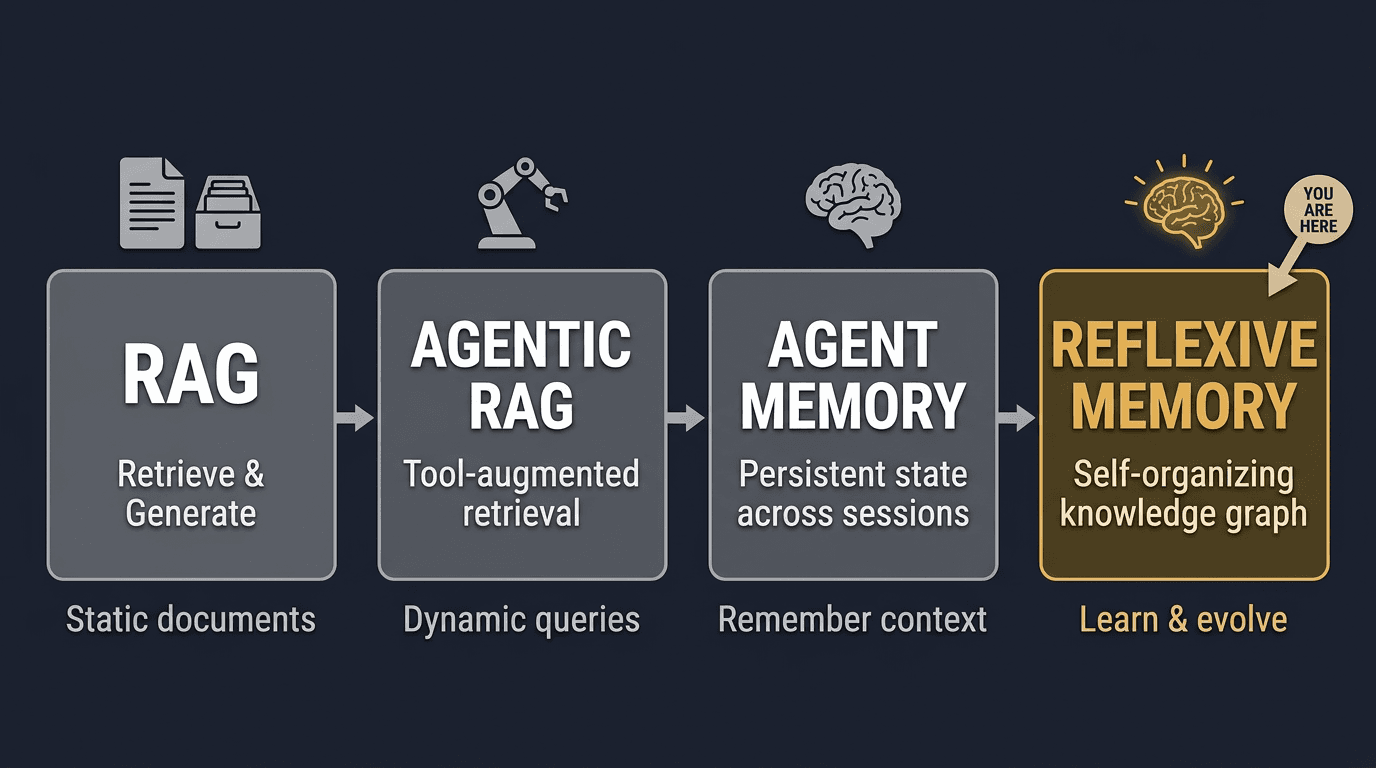
The three stages of agent knowledge
In late 2024, researcher Leonie Monigatti published a framework that crystalized what many practitioners were feeling: AI agents were evolving through three distinct stages of knowledge access. Her framing, “RAG to Agentic RAG to Agent Memory,” became a touchstone for the community.
Here is the progression, simplified:
2023
RAG
Read-only, one-shot
“How to retrieve”
Vector search over static documents. The agent reads, but never writes. Every session starts from the same corpus.
2024
Agentic RAG
Read-only via tools
“When to retrieve”
The agent decides when to search, which index to hit, and how to combine results. Still read-only: the knowledge base is managed by humans.
2025+
Agent Memory
Read-write via tools
“How to manage knowledge”
The agent stores decisions, lessons, and preferences. It queries its own history. Knowledge accumulates across sessions.
Most teams today are somewhere between stages two and three. They have retrieval. They might even have an agent that writes to a vector store. But that is where most systems stop.
Stage three introduces a harder question: what happens when the memory grows?
The missing stage: memory management at scale
In early 2026, an X user known as JUMPERZ published a comprehensive checklist of 31 capabilities that a complete agent memory stack should have. The post gathered 1,900+ bookmarks and became a de facto scorecard for the space.
The checklist goes well beyond “store and retrieve.” It covers deduplication, contradiction detection, temporal decay, intelligent forgetting, behavioral analysis, multi-agent coordination, and more. These are not features you bolt on later. They define whether your memory system actually works at session 100 the way it worked at session 1.
We scored OMEGA against all 31 items. The result: 24 of 31. The gaps are intentional: OMEGA is a CLI-first tool for developers, not a consumer app with a mobile client or browser extension.
OMEGA scorecard: 24/31
| Capability | OMEGA | Notes |
|---|---|---|
| Persistent storage | ✓ | SQLite, local-first |
| Semantic search | ✓ | bge-small ONNX, local |
| Typed memories | ✓ | decision, lesson, fact, preference, +5 more |
| Graph relationships | ✓ | relates, contradicts, evolves, supersedes |
| Temporal decay | ✓ | Configurable TTL + access-weighted scoring |
| Intelligent forgetting | ✓ | Compaction, stale detection, TTL expiry |
| Contradiction detection | ✓ | Cross-encoder at store time + reflect audit |
| Cross-encoder reranking | ✓ | Local ONNX, zero API calls |
| Session checkpointing | ✓ | omega_checkpoint / omega_resume_task |
| Auto-capture hooks | ✓ | PostToolUse hooks for automatic storage |
| Behavioral analysis | ✓ | 8 SQL extractors, zero LLM calls |
| Self-reflection | ✓ | omega_reflect: contradictions, evolution, stale |
| Multi-agent coordination | ✓ | Lock-free advisory system (Pro) |
| Entity scoping | ✓ | Per-project memory isolation |
| Knowledge graphs | ✓ | Edges with typed relationships |
| Cross-session learning | ✓ | Lessons and decisions persist |
| User preference tracking | ✓ | Protected from decay and cleanup |
| Context windowing | ✓ | omega_checkpoint saves full state |
| Deduplication | ✓ | Embedding similarity check at store time |
| MCP protocol | ✓ | 18 default core tools, stdio transport |
| Privacy / local-first | ✓ | Zero API keys, all data on disk |
| Cloud backup | ✓ | Encrypted sync (Pro) |
| Plugin system | ✓ | Extensible via MCP |
| Benchmark-validated | ✓ | 95.4% on LongMemEval |
| Multi-modal memory | — | Text only (images planned) |
| Voice interface | — | Not applicable (CLI-first) |
| Browser extension | — | Not applicable |
| Mobile app | — | Not applicable |
| Real-time collaboration | — | Async coordination only |
| Fine-tuning integration | — | Not applicable (retrieval-based) |
| Pricing tier for teams | — | Solo developer focus |
But even 24/31 is not the full story. A checklist tells you what features exist. It does not tell you whether the memory gets better over time. That requires a different capability entirely.
omega_reflect: the self-improvement pattern done right
Some agent frameworks have experimented with self-modifying memory. The most common pattern: the agent rewrites its own system prompt (often called SOUL.md or similar) at the end of each session. The new prompt replaces the old one. No versioning. No human review.
This is fragile for three reasons:
- No rollback. If the agent writes a bad instruction, it compounds. Each session builds on the corrupted version.
- No audit trail. You cannot see what changed or why. The agent overwrites its own history.
- No human gate. The rewrite happens automatically. By the time you notice, the damage is done.
OMEGA takes a different approach with omega_reflect. Instead of rewriting anything, it performs read-only analysis of existing memories and surfaces findings for human review. Three actions, zero side effects.
Action 1: contradictions
Over hundreds of sessions, your agent will inevitably store conflicting information. “Use PostgreSQL for the auth service” in January, “Migrate auth to SQLite” in March. Both are valid decisions, but only one is current.
omega_reflect(action="contradictions", topic="auth database") retrieves all memories related to a topic, runs pairwise comparison using a cross-encoder model (locally, zero API calls), and returns pairs that conflict, ranked by confidence.
> omega_reflect action="contradictions" topic="auth database"
Found 2 potential contradictions in 8 memories:
1. [HIGH confidence: 0.91]
Memory #142 (decision, Jan 12): "Use PostgreSQL for auth service"
Memory #287 (decision, Mar 03): "Migrate auth service to SQLite"
→ These appear to conflict. The newer decision may supersede.
2. [MEDIUM confidence: 0.73]
Memory #98 (fact, Dec 28): "Auth tokens stored in Redis"
Memory #287 (decision, Mar 03): "Migrate auth service to SQLite"
→ May conflict depending on whether tokens moved with the migration.
Action: Review and resolve. Use omega_store to record which decision is current.Action 2: evolution
Decisions evolve. Your understanding of a topic deepens. omega_reflect(action="evolution", topic="deployment strategy") traces how memories on a topic changed over time. It follows graph edges (evolves, supersedes) and sorts by timestamp to show the full arc.
> omega_reflect action="evolution" topic="deployment strategy"
Evolution of "deployment strategy" (5 memories, 3 months):
Dec 05 [decision] "Deploy via Docker Compose on a single VPS"
↓ evolves
Jan 14 [decision] "Move to Railway for zero-config deploys"
↓ supersedes
Feb 02 [decision] "Railway costs too high, switch to Fly.io"
↓ evolves
Feb 18 [decision] "Add Fly.io health checks and auto-scaling"
↓ evolves
Feb 21 [lesson] "Fly.io machines need explicit stop-timeout for graceful shutdown"
Current understanding: Fly.io with health checks, auto-scaling, and explicit stop-timeout.Action 3: stale
Memory systems that only accumulate eventually drown in noise. Old facts about deprecated APIs, abandoned approaches, one-off experiments: they clutter search results and waste context tokens.
omega_reflect(action="stale") surfaces memories that have not been accessed in a configurable window (default: 30 days) and were never marked as protected types. User preferences, constraints, and behavioral patterns are excluded automatically.
> omega_reflect action="stale" days=30
Found 12 stale memories (not accessed in 30+ days):
1. Memory #34 (fact, Nov 15): "Node 18 LTS is the current version"
Last accessed: Nov 20 (94 days ago)
2. Memory #67 (decision, Dec 01): "Use Prisma ORM for the prototype"
Last accessed: Dec 10 (74 days ago)
3. Memory #89 (fact, Dec 14): "OpenAI rate limit is 60 RPM on tier 1"
Last accessed: Dec 14 (70 days ago)
... 9 more
Skipped 24 protected memories (user_preference, constraint, behavioral_pattern).
Action: Review and delete outdated entries, or access them to reset the staleness clock.The key design principle: omega_reflect never modifies anything. It reports. You decide. This is the difference between a self-improving system and a self-corrupting one. The human stays in the loop.
The fourth stage: reflexive memory
If stage three is “agent memory” (read-write), the emerging stage four is what we call reflexive memory: a system that can audit its own knowledge, trace how decisions evolved, identify what is stale, and surface contradictions for human resolution.
This is not autonomous rewriting. It is structured introspection with a human gate. The agent proposes; the human disposes.
The pattern works because it respects a fundamental constraint: agents are good at finding patterns across hundreds of data points (better than humans), but humans are better at judging which patterns matter (better than agents). omega_reflect combines both strengths.
Get started in 60 seconds
OMEGA installs with two commands. No API keys. No cloud account. Everything runs locally on your machine.
pip install -U omega-memory[server]
omega setupThat is it. Your agent now has persistent memory with semantic search, contradiction detection, temporal decay, and reflexive analysis. All core MCP tools are available immediately.
To try omega_reflect on your existing memories:
# Find contradictions in your project decisions
omega_reflect action="contradictions" topic="architecture"
# Trace how your deployment strategy evolved
omega_reflect action="evolution" topic="deployment"
# Surface memories you haven't touched in 30 days
omega_reflect action="stale" days=30Related reading